
Recent advances in LLMs have demonstrated increasingly powerful reasoning capabilities, primarily through eliciting chain-of-thought outputs from models. While these methods have proven effective, they rely on discrete, tokenized representations of reasoning steps. A recent research paper from Meta introduces a novel approach that steps away from this paradigm: reasoning in continuous latent space rather than through explicit language tokens.
Recently, I’ve been quite interested in the increasingly popular trend of reasoning LLMs. So when I saw “Training Large Language Models to Reason in a Continuous Latent Space” in Meta FAIR’s recent paper flurry, I was intrigued. This was an interesting read which made me reflect on how LLMs use chain-of-thought (CoT). For our purposes, we’ll define CoT as the pattern of having an LLM generate step-by-step reasoning text before producing an answer. CoT has become a basic strategy to improve the model’s ability to perform well on harder reasoning tasks. This largely started with the 2022 “Large Language Models are Zero-Shot Reasoners” paper, which found improvements in model outputs simply by adding “Let’s think step by step” to prompts.
COCONUT Approach
The “Continuous Latent Space” paper introduces a new chain-of-continuous-thought (“COCONUT”) method for training reasoning behavior into models. Instead of having the model represent the chain-of-thought steps in text – or symbols that are ultimately mapped to text – they encoded the steps in a continuous latent vector, where a state from each step is fed into the model at subsequent time steps as the new input. By doing so, the system is able to use the LLM in a non-linguistic, continuous space for reasoning. The paper provides evidence of something which, upon reflection, is quite intuitive: reasoning can happen outside of language, and can be more powerfully expressed in non-linguistic symbols.
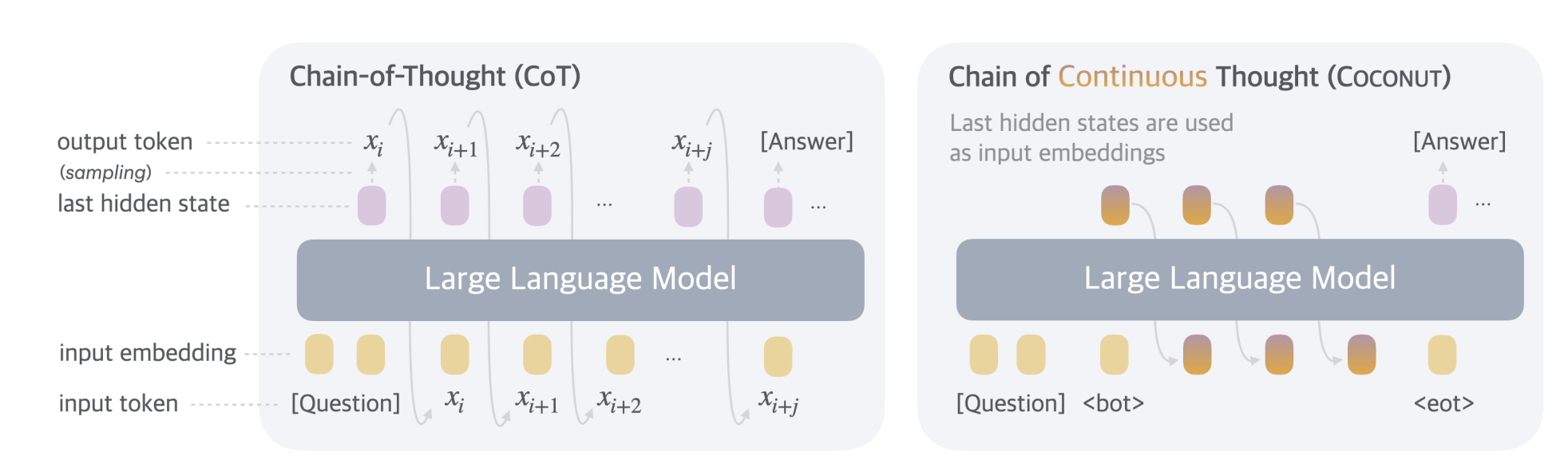
In some ways this isn’t surprising. If we recall the idea that “Language Modeling is Compression”, it’s not shocking that there are more information theoretically concise ways to express reasoning steps than with language tokens. If we think of a typical CoT, much of it looks like something like this:
Question: If a train leaves City A at 9:00 AM traveling at 60 mph and another train leaves City B at 10:00 AM traveling at 80 mph toward City A, how far from City A will the trains meet if the distance between the cities is 300 miles?
Reasoning:
- Okay, let’s see. Train A starts at 9:00 AM and travels at 60 mph. By 10:00 AM, when Train B leaves, Train A has traveled… oh wait, hold on, that’s not right. I should first calculate the time difference.
- Ah, right! In that first hour, Train A travels $60 \text{ miles}$, since $60 \text{ mph} \times 1 \text{ hour} = 60 \text{ miles}$.
- So now the distance between them is $300 - 60 = 240 \text{ miles}$. Okay, got it so far. Now both trains are moving toward each other at a combined rate of… wait, did I add that correctly?
- The speeds are $60 + 80 = 140 \text{ mph}$. Yeah, that’s right—combined rate of $140 \text{ mph}$. Sorry about the confusion earlier!
- At this combined rate, the time for them to meet would be $\frac{240}{140}$. Let me simplify that… uh, no, wait! Did I subtract the initial distance correctly earlier? Yeah, I did, never mind.
- Simplifying $\frac{240}{140}$, we get… oh no, wait! That’s $24 / 14$… uh, no, $12 / 7$! Yeah, so $\frac{12}{7} \text{ hours}$.
- Okay, converting that to hours and minutes… hold on, that feels weird. $\frac{12}{7} \times 60$ … actually, let’s just approximate this. It’s about $1.71 \text{ hours}$.
- Wait, no, not approximate! Stick with $\frac{12}{7}$ hours. So, the trains meet $\frac{12}{7} \text{ hours}$ after 10:00 AM. That’s, uh, around… no, hold on! $10 + 1.71 = 11:43 \text{ AM}$. Phew.
- Distance-wise, Train A has traveled $60 \text{ mph} \times 2.43 \text{ hours}$ … wait, did I just add the hours wrong again? Oh, right. No, it’s fine this time!
Just at a surface level, much of the CoT comprises of phrases like “Oh wait, hold on, that’s not right” and “hold on, that feels weird”, etc. These reflections are useful when reasoning within the linguistic space because they emulate human step-by-step reasoning, and encode the ability to self-correct and backtrack when a particular reasoning path fails. However, they also add significant noise and redundancy. Training on CoT traces allows the model to develop these patterns of self-correction, but in a fairly verbose way.
COCONUT Training
The authors train in this ability to use a latent space representation for reasoning by first training the model on textual CoT traces, and iteratively replaces parts of the CoT with continuous thought states:
As shown in Figure 2, in the initial stage, the model is trained on regular CoT instances. In the subsequent stages, at the $k$-th stage, the first $k$ reasoning steps in the CoT are replaced with $k × c$ continuous thoughts, where $c$ is a hyperparameter controlling the number of latent thoughts replacing a single language reasoning step.

Figure 2: Training procedure of Chain of Continuous ThoughtArxiv
This means the model has two modes: a linguistic mode and a reasoning mode, which are discrete and continuous, respectively. The authors note that in open-ended prompting, it becomes challenging to know when to switch between these modes. They propose two approaches:
a) train a binary classifier on latent thoughts to enable the model to autonomously decide when to terminate the latent reasoning, or b) always pad the latent thoughts to a constant length. We found that both approaches work comparably well. Therefore, we use the second option in our experiment for simplicity, unless specified otherwise.
While the second approach does seem simpler from an implementation perspective, the binary classifier approach seems more robust to me. I find it fascinating that a model which could autonomously decide when it needs to apply more or less reasoning to a problem. It’s a bit of a reach from the results in this paper, but if such an autonomous model were trained successfully, that would indicate to me a new level of metacognition that we’ve only recently seen hints of from frontier models.
Advantages of Continuous Representation
My understanding is that transitioning the reasoning process to a continuous spaces allows the model to learn more concise representations of the reasoning process. Reasoning in continuous spaces both allow for richer representations of the reasoning – since the intermediate steps don’t need to be collapsed back into discrete tokens – and because these continuous representations can be learned.
The idea of encoding latent thoughts into a continuous vector isn’t exactly new. I’ve seen papers exploring the use of “pause” or “…” tokens in reasoning steps, as a way of having the LLM perform computation for “real” before producing tokens for its output chain (e.g. this paper). COCONUT builds off this in making CoT reasoning explicit, then further generalizes these token “pauses” into a system wherein the representation of “thought” is not done in discrete tokens.
The primary result of COCONUT is that continuous CoT is that using the latent space for reasoning significantly improves the ability for the model to reason. They found that not only could latent space reasoning outperform discrete CoT, but also that the model learned improved planning abilities.
Implications for Interpretability
It’s not a costless improvement though: One aspect that seems valuable of chain-of-thought traces is the ability to interpret how a model arrived at its answer, by just inspecting the raw model output. As an interpretability measure, having the CoT in pure text tokens is quite useful. There are concerns that the CoT may be unfaithful to the actual reasoning used by the model: for example, the model might be learning to stenographically hide reasoning that is distinct from the face-value reasoning of the outputted CoT. However, as a baseline prior, it definitely seems like the CoT offers some insight into the reasoning steps of the model.
With continuous CoT, auditing the output of an internal reasoning chain is inherently non-interpretable by a human reader. This appears to be a tradeoff that you have to make: if the system operates in a continuous state space during reasoning, it will be very challenging to map that latent space back to interpretable words.
Reading Between o1’s Lines
Epistemic status: Uninformed speculation.
In the recent o1 technical report from OpenAI, red-teamers (such as Apollo Research) were not given access to the raw CoT traces. These are also not available to ChatGPT/API users. Previously there seemed to be policy reasons for this: OpenAI did not want to release CoT traces because they could be used to train reasoning models, which would erode OpenAI’s competitive edge. However, from an interview with Apollo Research’s Alexander Meinke, it sounds like with the full o1 model there were technical reasons why the full CoT could not be released to red-teamers.
If we’re somewhat conspiratorial, this could be because o1 uses non-discrete CoT, at least partially. Going over the o1 system report, there’s not much evidence for this, however. This quote, in particular, seems pretty solid evidence against non-discrete CoT:
In addition to monitoring the outputs of our models, we have long been excited at the prospect of monitoring their latent thinking. Until now, that latent thinking has only been available in the form of activations — large blocks of illegible numbers from which we have only been able to extract simple concepts. Chains-of-thought are far more legible by default and could allow us to monitor our models for far more complex behavior (if they accurately reflect the model’s thinking, an open research question).
So, 🤷♂️ :shrug: … This Lesswrong post has some additional speculation on what o1 is doing under-the-hood. As a lay person, none of these seem like hard blockers for the unavailability of the CoT. If OpenAI is using the CoT traces for safety filtering, as they say in the system report, it seems strange that these would be unavailable to release in an external form for any reason other than they weren’t actually human legible.
We already do know that OpenAI has a summarization model which summarizes and (partially) obfuscates the raw CoT:
We surface CoT summaries to users in ChatGPT. … We leverage the same summarizer model being used for o1-preview and o1-mini for the initial o1 launch. … We trained the summarizer model away from producing disallowed content in these summaries. We find the model has strong performance here.
However, the statement that they used the same summarization model for o1 as o1-preview and o1-mini makes me update slightly against the possibility of non-discrete reasoning tokens. As does the use of English descriptions for the o1 CoT in the system report.
The recent release of Qwen’s QwQ reasoning model – which uses entirely discrete reasoning – also shows that it’s definitely possible for discrete model to have strong performance.
Overall, I think it’s unlikely that o1 uses something like COCONUT – I’d predict somewhere in the neighborhood of a 20% likelihood.
Conclusion
So, while traditional, text-based CoT reasoning has become a quite common technique for eliciting improved reasoning performance out of LLMs, the rise of explicit “reasoning models” changes this landscape significantly – both in terms of model structure, and the type of prompting that is needed for optimal model performance. COCONUT and other new ideas for sampling models suggests that there exists a plethora of low-hanging fruit for extending LLMs to be better reasoners. If latent space reasoning does offer a nontrivial improvement in performance, as the COCONUT paper suggests, I suspect that this technique will be baked into frontier models – even at a hit to interpretability.
Cover & Footer images by Recraft v3