
This post gives a technical overview and architectural justification for my latest project, corral — a serverless MapReduce framework.
I’ve been working recently with Hadoop and Spark for a class I help teach. PySpark is fantastic, but Hadoop MapReduce never really “clicked” for me until I found mrjob. The concept of MapReduce is incredibly powerful, but the amount of boilerplate needed to write even a simple Hadoop job in Java is, in my opinion, rather off-putting.
Hadoop and Spark also require at least some infrastructure knowledge. Services like EMR and Dataproc make this easier, but at a hefty cost.
There have been past rumblings about using Lambda as a MapReduce platform. AWS published a (limited) reference architecture and there are some enterprise solutions that seem to be taking this approach as well. However, I couldn’t find a fully developed open source project that took this approach.
Around the same time, AWS announced native Go support for Lambda. Go’s short startup time, ease of deployment (i.e. single-binary packages), and general speed made it a great candidate for this project.
My idea was this: use Lambda as an execution environment, much like Hadoop MapReduce uses YARN. A local driver coordinates function invocation, and S3 is used for data storage.

The result is corral, a framework for writing arbitrary MapReduce applications that can be executed in AWS Lambda.
A Golang Interface for MapReduce
As Go famously doesn’t have generics, I had to scratch my head a bit to think of a compelling interface for mappers and reducers. Hadoop MapReduce has a large degree of flexibility in specifying input/output formats, the way records are split, and so on.
I considered using interface{} values for keys and values, but in the words of Rob Pike, “interface{} says nothing”. I decided on a minimalist interface: keys and values are strings. Input files are split by newlines. These simplifying assumptions made the implementation of the whole system simpler and cleaner. Hadoop MapReduce wins as far as customizability, so I decided to go for ease-of-use.
I’m happy with the final interface for Map and Reduce (some of which was inspired by Damian Gryski’s dmrgo):
type Mapper interface {
Map(key, value string, emitter Emitter)
}
type Reducer interface {
Reduce(key string, values ValueIterator, emitter Emitter)
}
type Emitter interface {
Emit(key, value string) error
}
ValueIterator has just one method: Iter(), which iterates over a range of strings.
Emitter and ValueIterator hide a lot of internal framework implementation (shuffling, partitioning, filesystem interactions, etc). I’m also pleased that I decided on using an iterator for values instead of a normal slice (which would perhaps be more idiomatic), as an iterator allows for more flexibility on the framework’s side (i.e. to lazily stream values instead of having them all in memory).
Serverless MapReduce
From the framework side of things, it took me a while to determine a performant way to implement MapReduce as a completely stateless system.
Hadoop MapReduce’s architecture gives it the benefits of…
- Persistent, long-running worker nodes
- Data locality at worker nodes
- Abstracted, fault-tolerant master/worker containers via YARN/Mesos/etc.
The last 2 aspects of this are fairly easy to replicate with the AWS stack. Bandwidth between S3 and Lambda tends to be pretty good (at least for my purposes), and Lambda is built so that developers “don’t have to think about servers”.
The trickiest thing to replicate on Lambda is persistent worker nodes. Lambda has a maximum timeout of 5 minutes. So, a lot of the way that Hadoop approaches MapReduce no longer work.
For example, directly transferring data between a mapper worker and a reducer worker is infeasible because the mapper needs to be done “as quickly as possible”. Otherwise, you risk the mapper timing-out while the reducer is still working.
This limitation manifests itself most during the shuffle/partition phase. Ideally, mappers would “live” long enough to transfer data to reducers on-demand (even during the map phase), and reducers would “live” long enough to do a full secondary sort using their disk as spill-over for a large merge sort. The 5-minute cap makes these approaches tricky to infeasible.
In the end, I decided to use S3 as the backend for a stateless partition/shuffle.

Semantic Intermediate Filenames Used for Partition/Shuffle
By using “prefix-friendly” names for mapper output, reducers can easily select which files they need to read.
Dealing with input data was significantly more straightforward. Like Hadoop MapReduce, input files are split into chunks. Corral groups these file chunks into “input bins”, and each mapper reads/processes an input bin. The size of input splits and bins is configurable as needed.

Self-deploying Applications
One of the bits of corral that I was most excited about was that it’s able to self-deploy to AWS Lambda. I wanted it to be quick to deploy corral jobs to Lambda — having to manually re-upload deployment packages to Lambda via the web interface is a drag, and frameworks like Serverless rely on non-Go tools, which would be cumbersome to include.
My initial thought was that the built corral binary would upload itself to Lambda as a deployment package. This idea actually works… until you deal with cross-platform build targets. Lambda expects a binary compiled with GOOS=linux , so any binary compiled on macOS or Windows wouldn’t work.
I almost abandoned the idea at this point, but then I stumbled upon Kelsey Hightower’s Self Deploying Kubernetes Applications from GopherCon 2017. Kelsey described a similar approach, though his code ran on Kubernetes instead of Lambda. However, he described the “missing link” that I needed: Have the platform-specific binary recompile itself to target GOOS=linux.
So, in sum, the process that corral uses to deploy to Lambda is as follows:
- The user compiles their corral application targeting their platform of choice.
- Upon execution, the corral app recompiles itself for
GOOS=linux, and compresses that generated binary into a zip file. - Corral then uploads that zip file to Lambda, creating a Lambda function.
- Corral invokes this Lambda function as an executor for map/reduce tasks.
Corral is able to use the exact same source code as both a driver and remote executor by doing some clever inspection of the environment at runtime. If the binary detects that it’s in a Lambda environment it listens for an invocation request; otherwise, it behaves normally.
There used to be an embedded tweet here, back when Twitter was Twitter.
View the original on X →As an aside, the idea of self-uploading or self-recompiling applications is rather thrilling to me. I remember when I was taking a theory of computation class the concept of “self-embedding” programs (often referenced in the context of Undecidability proofs) were interesting, but I couldn’t think of a case in which you’d actually want a program with that level of internal reflection.
Self-deploying apps are, in a way, a pragmatic example of this idea. It’s a program that recompiles itself, uploads itself to the cloud, and invokes itself remotely (albeit through distinct code paths). Neat stuff!
Once deployed, the binary that corral uploads to Lambda conditionally behaves as a Mapper or Reducer depending on the input its invoked with. The binary that you execute locally keeps running and invokes Lambda functions during the Map/Reduce phases.

Corral Job Timeline
Each component in the system is running the same source, but there are many parallel copies running in Lambda (as coordinated by the driver). This results in the parallelism that makes MapReduce fast.
Treating S3 Like a File System
Corral, like mrjob, tries to be agnostic to the filesystem it runs on. This allows it to transparently switch between local and Lambda execution (and allows room for extension, such as if GCP begins to support Go in cloud functions).
However, S3 isn’t really a filesystem; it’s an object store. Using S3 like a filesystem requires a bit of cleverness. For example, when reading input splits corral needs to seek to a certain portion of a file and begin reading. By default, a GET request to S3 returns the entire object. This isn’t great when your objects are potentially tens of gigabytes.
Fortunately, you can set a Range header in S3 GET requests to receive chunks of objects. Corral’s S3FileSystem leverages this, downloading chunks of an object at a time as necessary.
Writing to S3 also requires a bit of thought. For small uploads, a standard “PUT Object” request is fine. For larger uploads, multipart uploads become more appealing. Multipart uploads allow for the functional equivalent of writing to a local file; you “stream” data to a file, instead of retaining it in memory to write all at once.
To my surprise, there wasn’t a great S3 client that provided io.Reader and io.Writer interfaces. s3gof3r is the closest thing I could find; it’s pretty good, but (in my experience) leaks so much memory that I couldn’t use it in the memory-limited Lambda environment.
Memory Management in Lambda
While AWS Lambda has been gaining steam for the past few years, it feels like the tooling for profiling Lambda functions is lacking. Lambda does, by default, log to Cloudwatch. If your function panics, a stack trace is logged. As such, “crashing” errors are relatively straightforward to debug.
However, if your function runs out of memory or time, all you’ll see is something like this:
REPORT RequestId: 16e55aa5-4a87-11e8-9c63-3f70efb9da7e Duration: 1059.94 ms Billed Duration: 1100 ms Memory Size: 1500 MB Max Memory Used: 1500 MB
Locally, tools like pprof are fantastic for getting a sense of where memory leaks come from. In Lambda, you have no such luck.
In an early version of corral, I spent hours tracking down a memory leak that ultimately was caused by s3gof3r. Since Lambda containers are reused, even small memory leaks will result in eventual failure. In other words, memory usage persists across invocations — a leaky abstraction (no pun intended).
It’d be great to see better profiling tools for AWS Lambda, especially since Golang is a notably easy runtime to profile.
When Lambda Becomes Expensive
Ostensibly, the goal of corral is to provide a cheap, fast alternative to Hadoop MapReduce. AWS Lambda is cheap, so this should be a slam dunk, right?
Yes and no. The free tier of Lambda gives you 400,000 GB-seconds per month. This sounds like a lot but gets used up quickly by long-running applications.
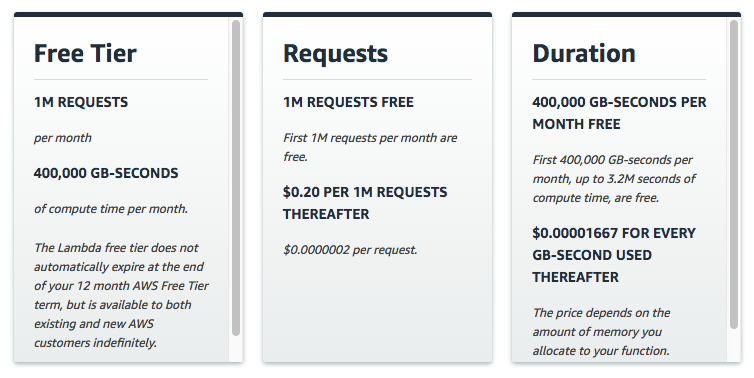
Lambda Pricing Scheme as of 4/29/2018
Ultimately, corral can still end up being very inexpensive. However, you’ll want to tune your application to use as little memory as possible. Set the maximum memory in corral as low as possible to reduce cost.
Time is an as-you-use-it resource in AWS Lambda — you’re charged for as many milliseconds as you use. Memory is billed by use-it-or-lose-it. If you set the max memory to 3GB but only use 500MB, you’re still paying for the full 3GB.
Performance
While not a primary design consideration, corral’s performance is fairly respectable. Much of this is due to the nearly infinite parallelism that Lambda offers. I used the Amplab “Big Data Benchmark” to get a sense of corral’s performance. This benchmark tests basic filters, aggregations, and joins.
As I anticipated, corral does quite well on filtering and aggregation. However, it falls flat on joins. Without a secondary sort, joins become expensive.
The Amplab benchmark tests up to ~125GB of input data. I’d be curious to do more benchmarking with around ~1TB of data to see if performance continues to scale more-or-less linearly.
More information and benchmark statistics can be found in the corral examples folder.
Conclusion
So that’s it: corral let’s you write a simple MR job, frictionlessly deploy it to Lambda, and run jobs on datasets in S3.

Running a word count job in Lambda
It’s also worth noting that I’m not wedded to the AWS ecosystem. Corral is mostly agnostic to Lambda and S3 so that, in the future, connectors to GCP’s Cloud Functions and Datastore could be added (if/when GCP adds Go support to CF).
On a personal note, I found this project to be quite rewarding to work on. There were many fewer resources online for building a MapReduce system than for using one, so there were some implementation details that I got to work out.
Feel free to make issues in the corral repository. I’m curious to see if there’s a big enough niche that this project fills to justify continued development. 😁