
Every once-in-a-while a game really sucks me in. Over my vacation in August, I got hooked on Wordscapes — a simple word game where you have to generate valid words from a bag of letters you’re provided to fill in a crossword puzzle. After a few hours playing this, I naturally began to wonder if there is an efficient algorithmic solution to this game.
Rules of the Game
In each round of the game, you’re given a set of letters that you can choose from and a crossword puzzle that displays your progress. You swipe the letters in order to form a word. If the word is (1) a valid word and (2) part of the current puzzle, the crossword puzzle fills in a row/column with the word you selected. You continue swiping words until you fill in the whole puzzle, at which point you’ve solved the round.

Example (Easy) Puzzle
To be clear, this is not a hard game. It isn’t timed and you aren’t penalized for trying nonsense combinations of words. A perfectly valid strategy is to manually brute force all possible combinations of letters.
There aren’t even that many combinations: The total number of possible letter sequences for any given puzzle is $\sum_{i=3}^n{i!}$ (Wordscapes doesn’t have any words with fewer than 3 characters). Seemingly, the number of available letters is capped around 7, so using a brute force strategy, you’d “only” have to try 5910 letter sequences in the worst case.
However, I was still interested in Wordscapes solver. The game has strong parallels to an anagram finder — that is, given a set of characters, list the words that can be formed using arrangements of those characters. Wordscapes differs in that words formed by any subset of the given characters is also a valid solution.
For the purposes of time, I just decided to focus on the “word finding” aspect of the game. One could probably write a full-solver given the shape of the crossword board, but I wasn’t as interested in that aspect.1
Algorithmic Approaches
Brute-Force Approach
The most naive approach is essentially powerset enumeration combined with an anagram finder. The idea is to find all subsets of the characters we have. For each set, we compute all possible orderings of the characters and check each word against a dictionary of known words.
First we generate character subsets…

…and then we check each permutation of these sets for valid words.

Why is this suboptimal? Well, clearly it’s incredibly inefficient. Given $n$ characters, we have $O(2^n)$ sets. For each set of size $m$, we have $O(m!)$ permutations to check.
Improving Brute-Force with Character Frequency Counting
One important thing to note is that Wordscapes uses ASCII-only characters — really, only A-Z. Also, note that we don’t really care about the ordering of characters in words, only their count.
Using the fact from above, we can improve our brute force solution by checking words against our candidate characters, instead of generating all possible candidate words. This is a common property of anagrams used in anagram checkers.
We can also be more efficient in storing counts by using an array of length 26 instead of a hash-set. This will (empirically) improve lookup time.
Our updated algorithm looks like this. For each word in the English dictionary:
- Count the occurrences of each character in the current word.
- We can “build” this word with our character set if the counts of each character in the word are less than or equal to the count of that character in our character set.
- From the dictionary, select the set of words that can be built with our character set.
Since we perform constant work on each word (we can simply filter out any words longer than the size of our character set, which ensures constant work), our runtime is linear w.r.t. the size of our English dictionary.
Trie-Based Approach
Another approach is to generate a trie from known valid words, and then traverse the tree using the set of characters we are given.
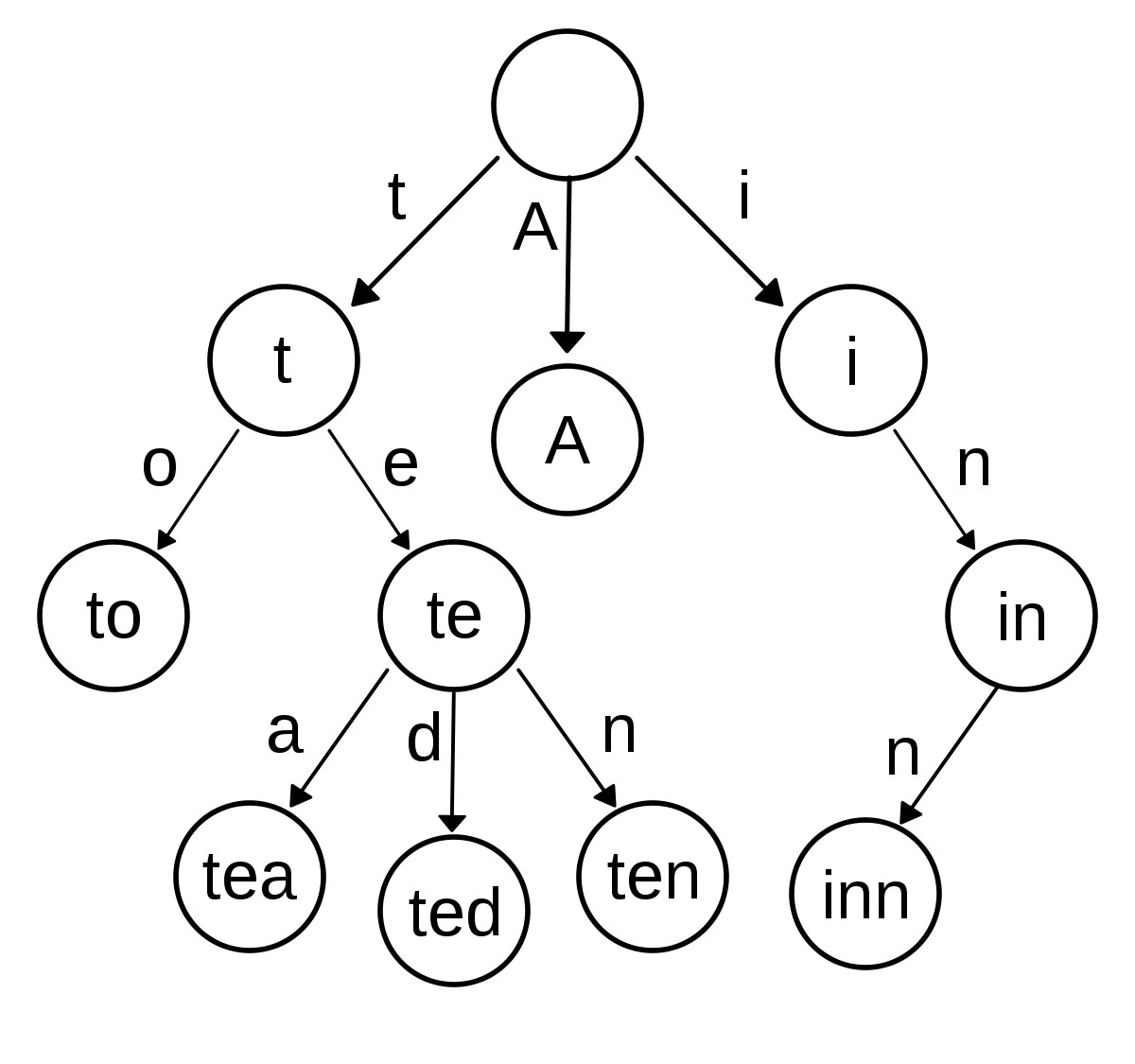
We still have to check every permutation of our character set. However, by doing some smart trie traversal, we can bail early on sequences that we know are invalid. For example, if we have the character set HATZQ and we traverse our trie with Q->T->Z, we’ll notice that there are no words that start with QTZ2, and we can “prune” the rest of the possible sequences for that have this prefix.
The big win here is that we don’t have to generate $2^n$ subsets — though, we still could investigate $n!$ paths. For English words, it’s likely we’ll only have to traverse a small subset of these $n!$ paths though (i.e. there aren’t many words that begin with “z”, so the number of paths we can traverse using “z” as the first character will be small).
Improving Performance with Pre-filtering
In all of the above approaches, we implicitly have a dictionary of all English words that we check against.
In practice, keeping a complete dictionary is unnecessary. For example, if our character set is BAREZL, then it’s pointless to include any words in our dictionary that are longer than 6 characters or have any letters other than the ones in our set. We can drastically improve the lookup time in our dictionary/trie by pre-filtering, discarding words that obviously cannot be constructed with our character set.
Benchmarks
So how does the performance of these approaches compare? I wrote implementations of the 3 approaches and benchmarked then with-and-without a pre-filtered dictionary.
Using the slowest approach (brute force without filtering) as the baseline (1x), here are the performance score in terms of speedup over the baseline (higher is better):
- Brute Force without filtering: 1x
- Brute Force with filtering: 3.76x
- Character Frequency without filtering: 3.56x
- Character Frequency with filtering: 8.69x
- Trie without filtering: 0.12x3
- Trie with filtering: 9.27x
Conclusion
In practice, with a relatively small set of characters, a filtered trie seems to be the most performant approach. However, for larger sized character sets, I’d imagine that the Character Frequency-based approach would fare better.
I wrote my implementations in Rust, which you can check out here. The code is a bit sloppy, as this was an experiment.
While much less ambitious, this post was inspired by Michael Fogleman’s excellent article about solving the game “Rush Hour”.
-
Generally, the set of words for any given character set is rather small. The additional puzzle complexity afforded by the crossword puzzle is more to jog a human player’s mind for potential words, and less to restrict the words you can play in the game. ↩︎
-
Though, there are several words that begin with the prefix “qt”. ↩︎
-
Unfortunately, constructing the entire trie from the English dictionary took much longer than brute force. ↩︎