
Over the past couple weeks, I’ve been working on an implementation of the Raft distributed consensus algorithm written in Go. It’s been a great exercise in “grokking by doing”. It’s one thing to understand an algorithm, and another thing to implement a correct instance of it.

The Raft Mascot
I’ve been working on top of the excellent lab code framework for the MIT 6.824 Distributed Systems course. Their Raft lab provided exactly what I wanted: an in-memory configurable network and a (fairly) rigorous test suite so you could focus on the actual Raft implementation without the surrounding boilerplate. Using someone else’s test suite (which, one imagines, has been run on hundreds students’ code) also made me more confident that my implementation was correct.
Understanding Raft
Raft is a consensus algorithm designed to perform log replication across an unreliable network. It’s usually framed as a “more understandable” version of its predecessor, Paxos.
The first thing I did for this project was to read the Raft paper. It’s only 18 pages long (less if you exclude the sections about how they validated that it was “more understandable” than Paxos). I also looked through this excellent visual explanation of the algorithm, and played around with the interactive Raft simulation on the Raft site.
Raft is, in theory, pretty simple: The idea is that you want to replicate a list of log entries across a set of nodes such that if an entry gets “committed” to the log, then no other node can commit any different log entry to the same position in the log. This ensures eventual agreement, given the ability of nodes to communicate.
Raft uses leader election to coordinate replication. Once a leader has been elected, it communicates new entries to all the other nodes (“followers”). Once a majority of followers have heard about a new entry, that entry can be committed. If a leader discovers that another server has become the leader (usually due to a timeout or network fault), it steps down and becomes a follower.
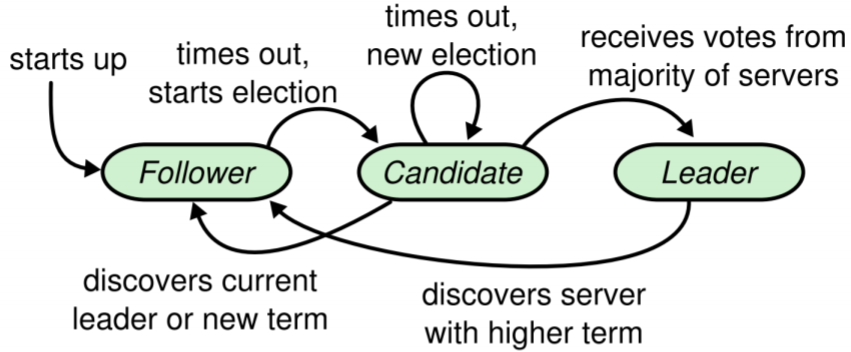
Node state machine
There’s some extra subtlety to how this all gets hooked up, but the cool thing about this approach is that it works even if network messages take arbitrary time, network messages get dropped, or nodes crash/restart. As long as all the nodes follow the protocol and a majority of them are online, Raft ensures strongly consistent log replication.
From Theory to Implementation
Reading the Raft paper was not difficult, and from the paper it’s also pretty easy to convince yourself of the safety of the algorithm. However, translating the algorithm into a functioning implementation is nontrivial. There are multitudinous ways that you can “break” the safety of Raft, just by forgetting to reset a timer or committing an off-by-one error in indexing. Raft is billed as being “easy to understand” – and it is! – but distributed consensus is still a complex problem. Raft relieves the inherent complexity of the algorithm (contra Paxos); however, writing safe concurrent code is still difficult.
Even with Go’s excellent concurrency and synchronization primitives, you have to
be quite careful to avoid data races and be mindful of critical areas where
locking is necessary. Fortunately, careful uses of sync.Mutex and enabling the
Go race detector in testing
made these issues infrequent.
The majority of the issues I ran into were due to my misunderstanding some detail of the Raft protocol. For example, I had a fun issue where leaders would occasionally overwrite logs that a follower had already committed. Eventually, I traced the issue as:
- An “invalid leader” (which had previously been separated in a network partition) came to power with an out-of-date log.
- The invalid leader tried to replicate to a follower, and in doing so would “back up” several epochs1 previous to latest epoch that the follower knew about.
- As a result, the invalid leader overwrote previous history agreed upon by a quorum, leading to different committed logs.
The root problem was that in my vote request code, I was enforcing that the last log index matched between the leader/follower without enforcing that the last log epoch match.
Another issue I had was related to an optimization that the MIT test suite requires you to implement: when a follower rejects a replication request, it should tell the server exactly where in the log the conflict occurs, so the server can immediately return a list of entries starting from the previous point of agreement. Without this optimization, the leader needs to send as many RPC messages as there is “confusion” between the leader and follower, which can prevent successful replication in cases where the leader and follower have divergent uncommitted logs and the network is particularly unreliable.
This issue was infrequent enough that it was difficult to reproduce, but eventually I tracked it down to an error I made, where the leader incorrectly updated the metadata it saved for the lagging follower, and instead of providing the “correct” set of logs, it would always provide a subtly incompatible list of logs, resulting in an infinite replication loop.
When debugging all of these issues, it was extremely helpful to have good (debug) logs to trace through. Printing a log every time a node changed state or performed an RPC made it possible to trace state changes through the system. This is easier when everything is actually running on the same machine via a simulated network – I now have a lot more sympathy for systems operators, and interest in distributed tracing.
# Example logs
[Node 1]: Starting election for term 1
[Node 2]: Becoming follower in term 1
[Node 0]: Becoming follower in term 1
[Node 1]: RequestVote -> Node 0: &{Term:1 Candidate:1 LastLog:0 LastTerm:0}; &{Term:1 VoteGranted:true}
[Node 1]: RequestVote -> Node 2: &{Term:1 Candidate:1 LastLog:0 LastTerm:0}; &{Term:1 VoteGranted:true}
[Node 1]: Elected leader! (for term 1)
[Node 1]: AppendEntries -> Node 0: &{Term:1 Leader:1 PrevLogIndex:0 PrevLogTerm:0 Entries:[] LeaderCommit:0}; &{Term:1 Success:true}
[Node 1]: AppendEntries -> Node 2: &{Term:1 Leader:1 PrevLogIndex:0 PrevLogTerm:0 Entries:[] LeaderCommit:0}; &{Term:1 Success:true}
It was a pretty fun exercise to build a toy Raft implementation, and I gained a deeper understanding of distributed consensus. I’d recommend this as a relatively-low-effort-for-high-reward distributed systems project.
Further Reading
- Students’ Guide to Raft: Great in-depth exploration into common Raft pitfalls.
- Implementing Raft - Eli Bendersky -
An excellent blog series describing implementing Raft in Go.
- The reference code for this series is available on Github as well, and was useful to consult.
Cover: Unsplash
-
The Raft paper uses “term” instead of “epoch”, but I think “epoch” provides more disambiguation. ↩︎