Over the past few months, I’ve been hard at work trying to reduce the latency of
workflows for one of the APIs that my team owns. Last week, I discovered a small
change that had a larger impact on reducing latency than 3 months of work.
Somewhat embarrassingly, that change was effectively “don’t call time.Sleep”.
For a bit of context, one of the APIs that we expose is an asynchronous API that goes through a complicated process with multiple stages, before finally returning some results. This workflow itself calls out to other asynchronous APIs, triggering operations in other services, and polling for these operations to complete.
Internally, this is represented as a state machine. An idealized version of that sorta looks like this:
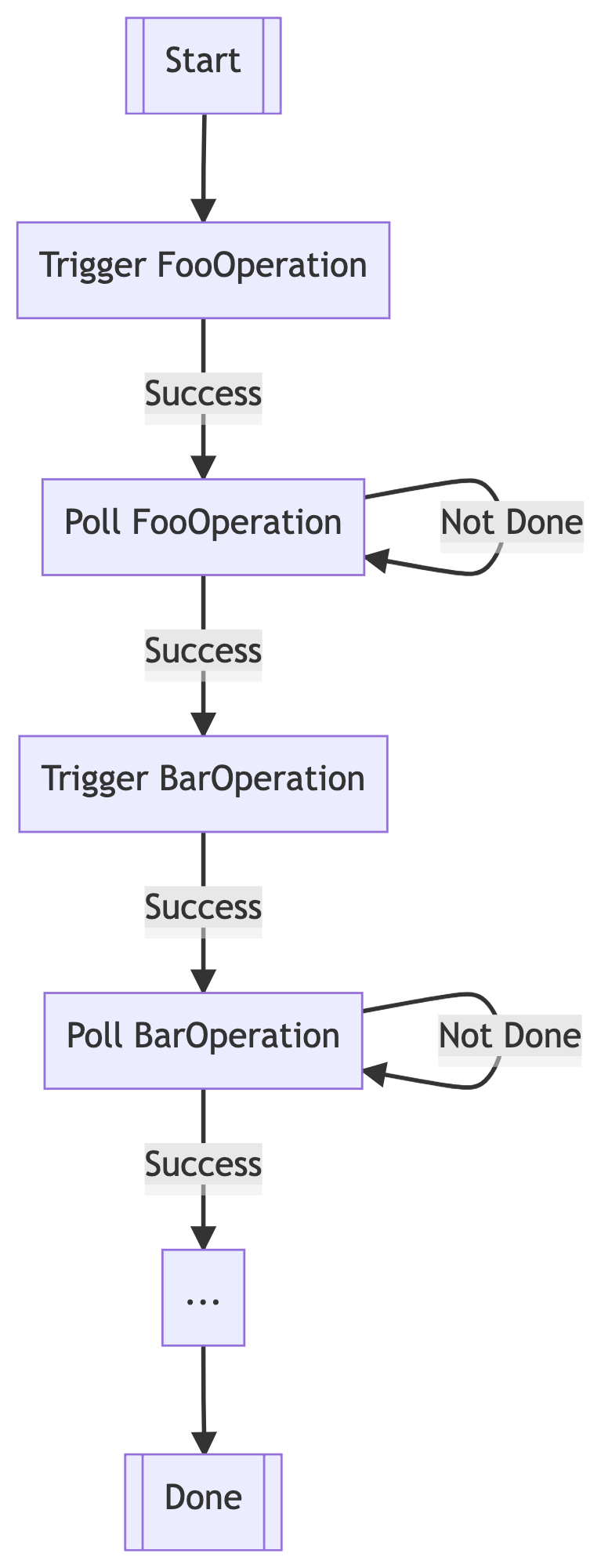
One of our peer teams using our service requested that we reduce service latency by something like ~50%. Sure, sounds like a fun challenge. After profiling our system performance some months ago, we realized that a significant bottleneck of the workflow latency was a particular dependent service, which accounted for the vast majority of the overall latency.
So, we went about replacing that dependency with a new, optimized service. Several design documents, security reviews, rollout plans, service turnups, and approximately 3 months later, that component was replaced, and we were beginning to hit our desired latency targets. Yay!
One day towards the end of this effort, I was tinkering with the server framework that executes our state machine and noticed something important about how it was implemented. Workflow execution occurs on worker machines; each worker would pick up the state of the operation, attempt to run the relevant state-specific logic, and then handle a state transition to the next state based on the result of that logic. Some steps need a delay before retrying, such as when polling operations from dependent services, to prevent “busy waiting”. These are still effectively state “transitions” – they’re self-loops back to the same state.
What I noticed is that the framework wasn’t distinguishing between the type of transition that was occurring – it just had a uniform “retry delay” for any state transition. Something like this:
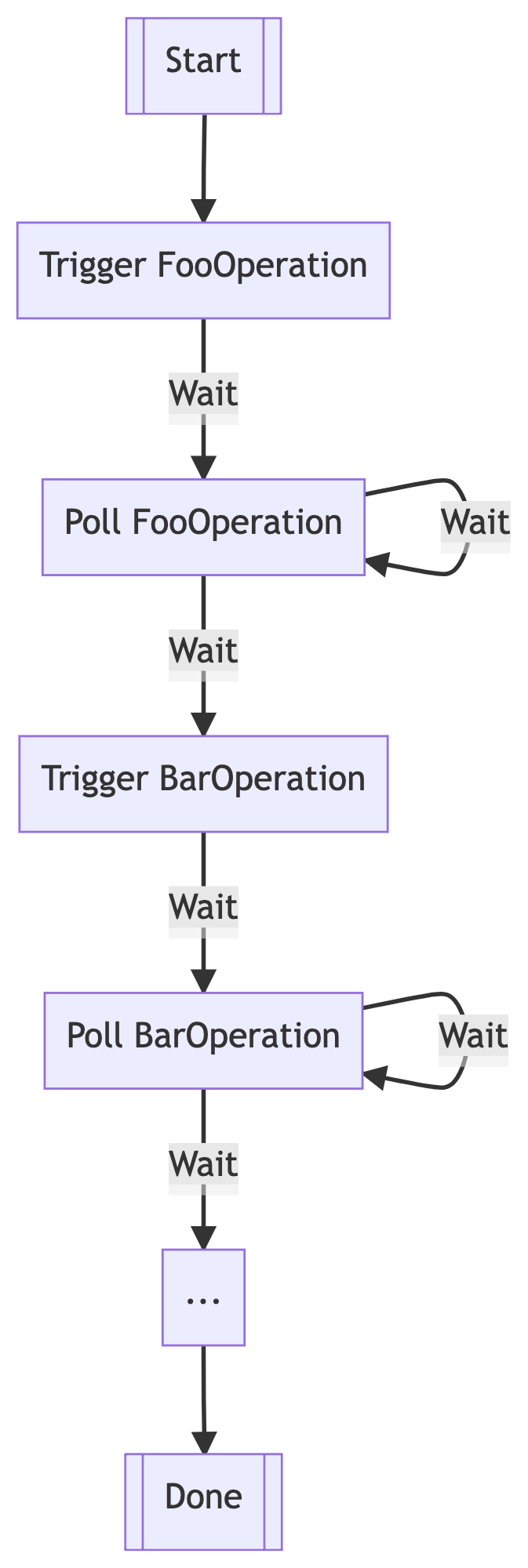
It’s desirable that the self-loops for a polling state should have some delay before retrying. But, critically, transitions to a new state do not need any delay.
This was the default configuration of the state machine framework, and as far as I could tell, none of the other services using this framework had ever overridden this behavior.
After a bit of tinkering, I discovered that it was possible to reschedule an operation to be immediately retried after a successful state transition, so that that the workflow behaved more like this:
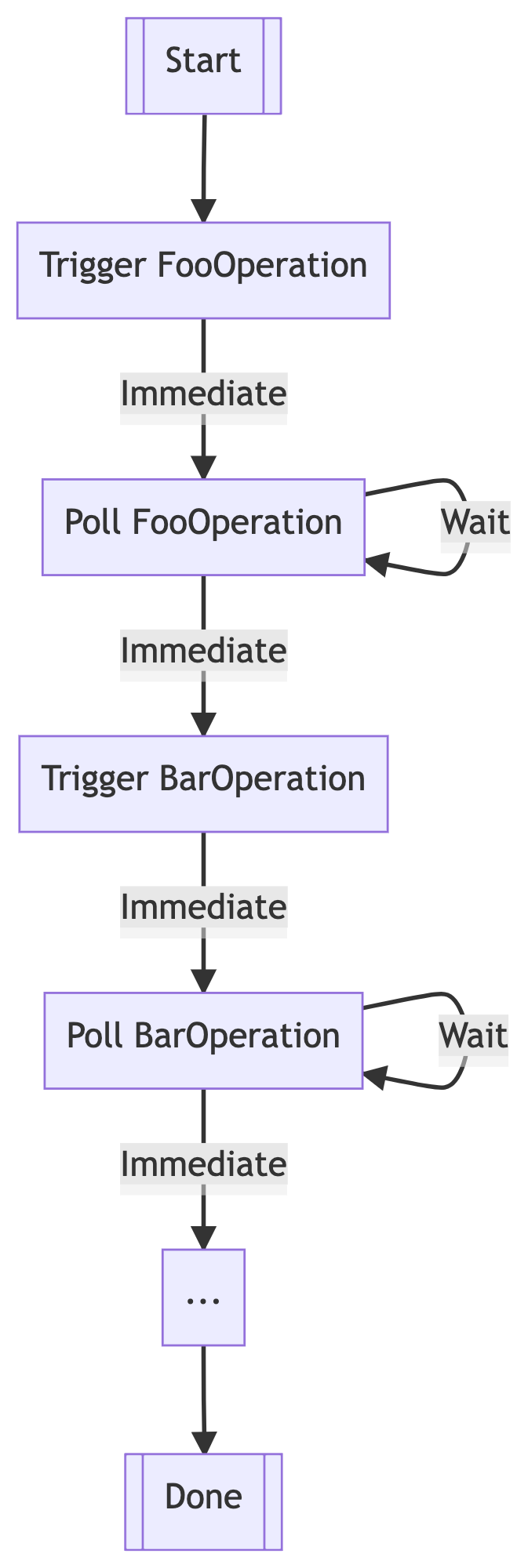
I didn’t really think much of this, maybe we’d shave off a few seconds. I submitted the change, and looked at our metrics the next day.
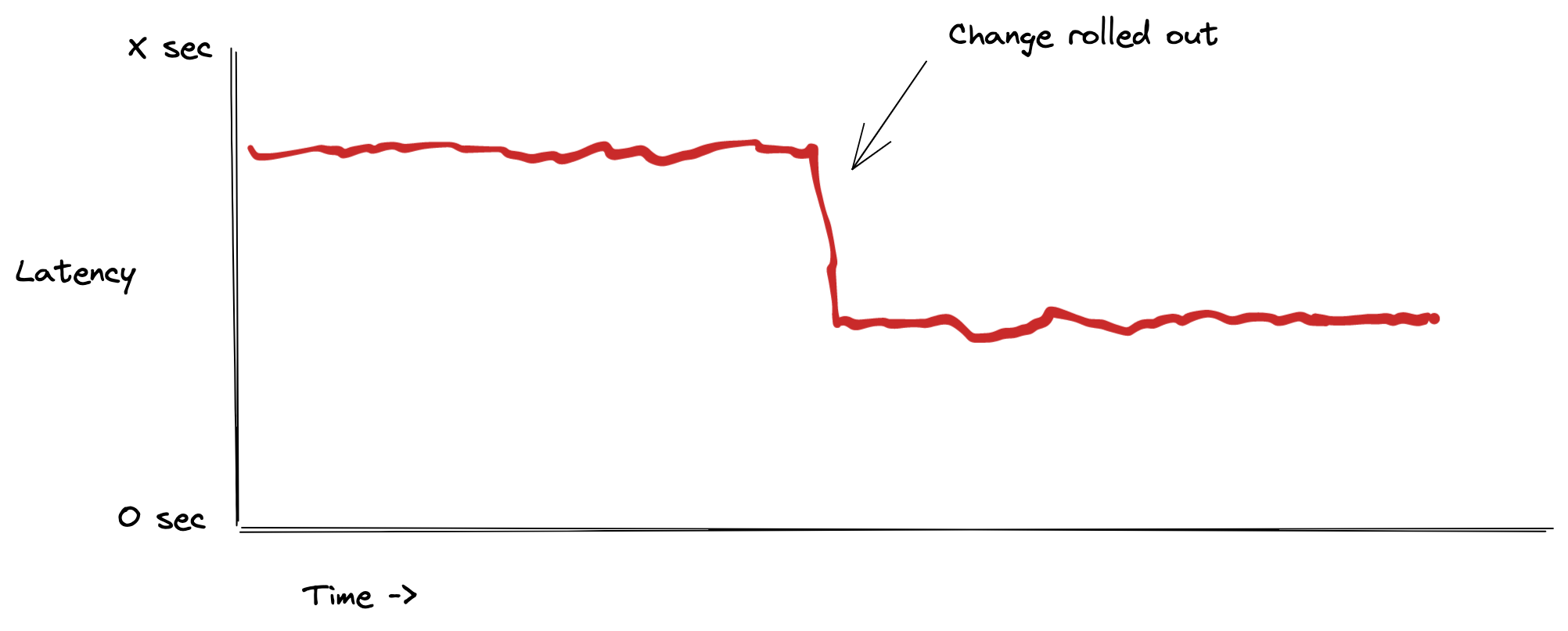
Observed Effect (Artist’s Rendition)
Oh. lol.
Not only did this improve latency in the specific workflow that I was
optimizing, it improved latency across all workflows. We essentially saved
NumSteps * RetryDelay seconds across the board. In workflows with a bunch of
steps, this was an embarrassingly nontrivial amount of time.
Long story short, this one change had about as much latency impact as the three month effort that I started this story with. (Fortunately, that architecture change brought us some other benefits, so it wasn’t completely redundant. – And, now we very comfortably exceeded our service targets, instead of just barely squeezing under the desired latency.)
If there’s a moral to this story, I think it’s that it’s worth rechecking your assumptions occasionally.
When we first created this service, latency was not a top concern. We chose a retry delay somewhat arbitrarily, and never revisited that decision. When we later went to profile our system latency, it didn’t occur to me that this was a parameter that could be changed – it just appeared as “black box” framework latency.
This class of “one weird trick” almost always – in retrospect – as either a stroke of genius, or incredibly obvious low-hanging fruit (depending on how familiar you are with the components involved 😉). Usually, it’s the result of poking at something that hasn’t been touched for a while, or rethinking how a component works given that the environment it operates in has changed since it was first created.
Peeking down an abstraction level or two, at opportune times, can result in cheap, high impact fixes.