
To be a well-calibrated predictor, you need to to be wrong (sometimes).
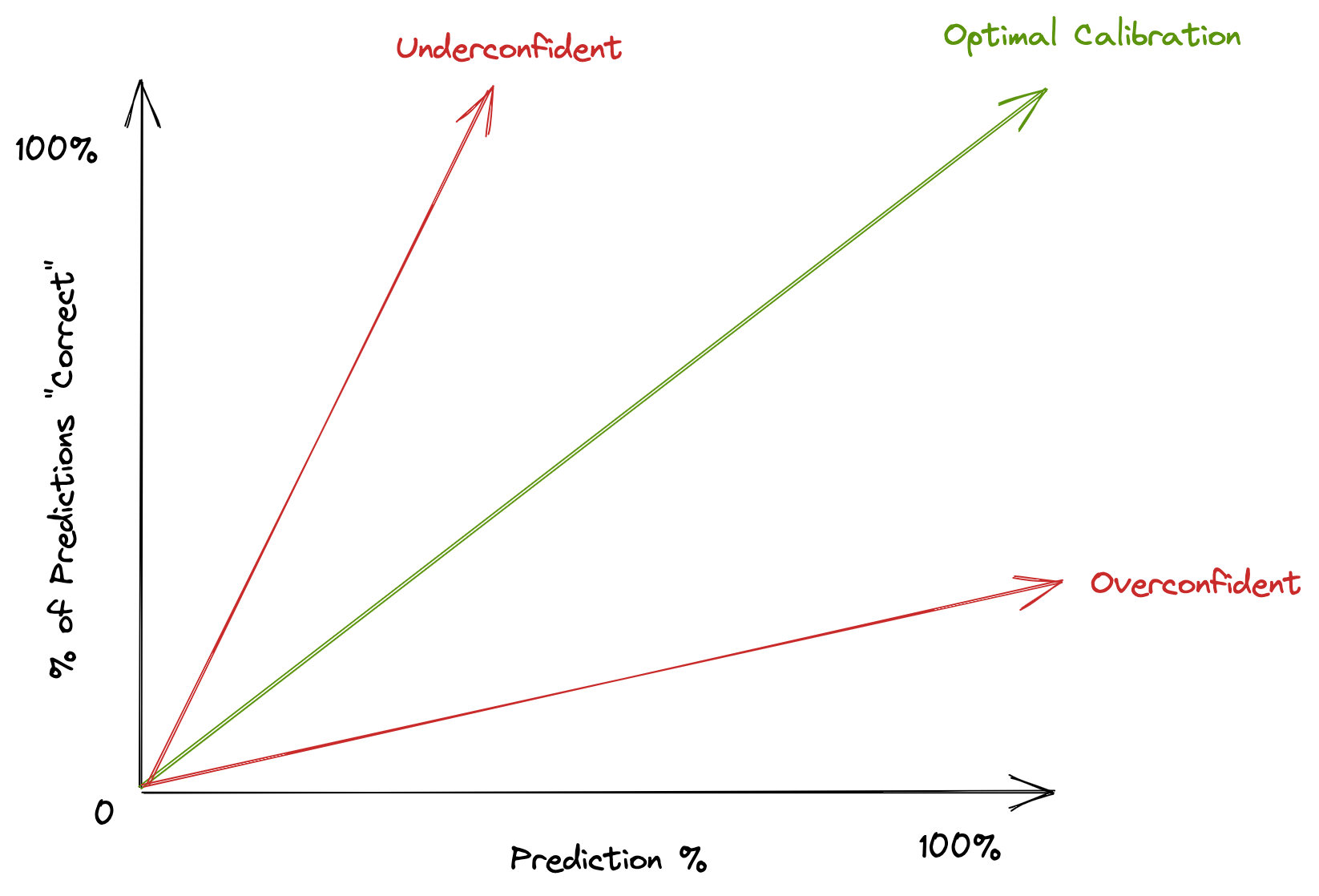
“Well-calibrated” means that if you predict something occurs with X% probability, then that event actually occurs X% of the time. Since predictions are often made on one-off events, another way of expressing calibration is that X% of predictions that you made with X% confidence should resolve in your favor. For example, if you make 100 predictions of 100 independent events, each with probability 75%, then you’d expect that (roughly) 75 of your predictions would be “correct”.
The corollary to this is that, in the same example, you’d expect that 25 of your predictions would be “wrong”. And this is a good thing. If you instead observed that only 5 of your predictions were “wrong”, then you would not be well-calibrated. Rather, you’d be significantly underconfident in your predictions.
Idealized Calibration Curves
I’ve been working for the past couple years to improve my prediction ability, and noticed that when I got a confident prediction wrong, I’d feel a sting of annoyance. For me, this threshold really sets in around 70%. If I’m >70% confident in my prediction, and it ends up being wrong, it feels bad.
The failure mode that I try to avoid is only making predictions that I’m actually very confident on, and then marking them down to, say, 70% confidence.1 This may make you feel good – fewer “wrong” predictions! – but is the path towards an underconfident calibration curve.
To be well-calibrated, you need to be wrong – even of events that you assign a moderately high probability to.
Again, if you make 100 predictions, each with 70%, and you don’t get any of those wrong, then your 70% probability estimates were very likely incorrect2. Being incorrect at the calibration level is worse than being wrong on any one event, because it indicates that your meta reasoning for assigning probabilities is inaccurate. Being “wrong” on any one event is itself not necessarily a problem. The world is stochastic. Even if your predictions are true representations of the probability of an outcome, this still means you’ll be wrong uncomfortably often.
Improving decision quality is about increasing our chances of good outcomes, not guaranteeing them.
– Thinking in Bets, by Annie Duke
Cover image: Discovery Park
-
To illustrate an extreme example of this, consider you make predictions of 100 events. Say you “know” that 70 events 100% chance of occurring, and 20 events have a 0% chance of occurring. If you were to make all 100 events as 70% probability, you’d still be mathematically “well-calibrated”, even though none of your assigned probabilities were correct. This is one downside of choosing which events to predict – it can be difficult to avoid this type of attractive sampling bias. ↩︎
-
At least, for some of the predictions that you made, of that set of 100. ↩︎