
For the last couple years, I’ve maintained a spreadsheet of personal predictions. It’s been a useful practice that I would recommend. “Personal” in this context has 2 meanings: first, that I don’t preregister or publicly publish these predictions; second, that the content of some of the predictions is personal in nature.
I’ve had predictions & forecasting on my radar for several years, but it really picked up during the pandemic and 2020 elections. There was a plethora of salient “in the world” things to predict, and in an environment of heightened epistemic uncertainty, checking your intuitions about how things “in the world” were progressing felt quite valuable.
More recently, the content of my predictions became less about
politics/economics/world events, and more focussed on my own life – e.g. “Will
I accomplish $PERSONAL_GOAL this year”, “Will $WORK_PROJECT ship on time”,
etc. To a large extent, I credit this to
Manifold Markets, which demonstrated the
value of predicting events that would otherwise seem trivial.
Even though I don’t publish these predictions, I keep myself honest with the following rules:
- Each prediction has a “predicted on” date, and after that date has passed the prediction cannot be edited in any way.
- Predictions are composed of (1) an outcome, and (2) a numeric probability that the outcome will occur.
- Each prediction must have a clear yes/no resolution criteria. If no yes/no is easily determinable, the prediction resolves as ambiguous (which has no impact on scoring).
You can get a flavor for how this looks in spreadsheet form here1:

(Click to expand)
Benefits
This practice has several noticeable benefits. First, you can plot a calibration curve to see if you’re wrong an appropriate proportion of time. Here’s mine for 2022, as of today, composed of 215 resolved predictions:
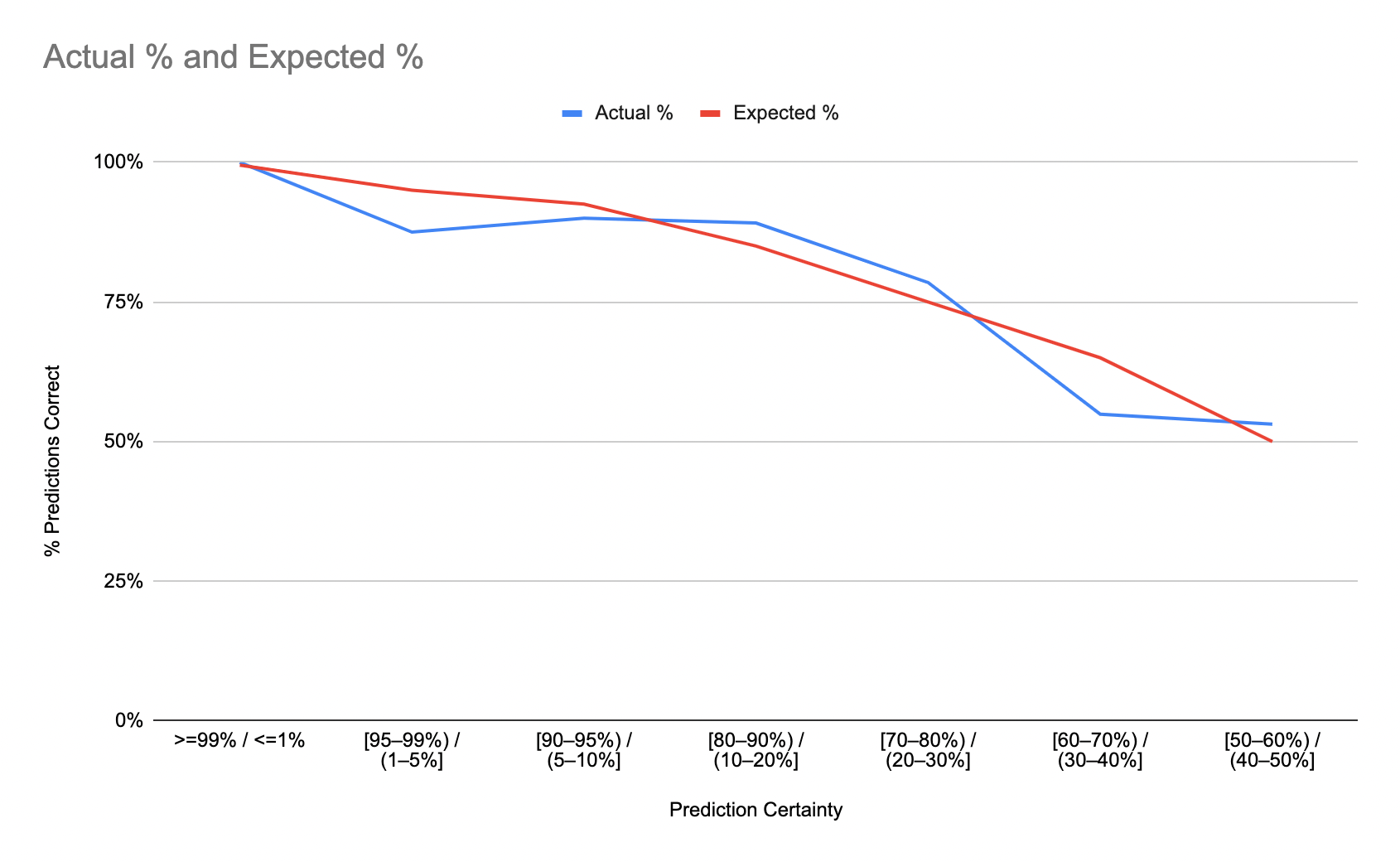
2022 Calibration
(The thing that stands out to me is that my predictions 60-70% range end up being more like 50/50)
Second, you have a record of “surprises”. Most of the time, predicting something correctly isn’t that interesting. Your mental model produced a prediction that agreed with the world, so you don’t need to perform any model updates. When you get something wrong (especially wildly wrong) that’s when the practice becomes valuable. Keeping a record of wrong predictions is a hedge against hindsight bias. When the record is there in front of you – that you believed something with high credence that turned out to be incorrect – it’s hard not to do some sort of substantive reflection on what caused you to be over-/under-confident.
Feedback Loops & Prediction Duration
Until 2022, most of my predictions were longer-term year-long predictions (in the style of the lists linked here). However, I think shorter-term predictions tend to be more immediately useful, if your goal is to get better at predicting. There’s value in predicting longer-term trends, but so much “stuff” changes in the world between when you make the prediction and when it resolves, that the appropriate post-resolution updates to your mental models can be hard to determine.
Shorter-term predictions (resolving in ~weeks/months instead of ~1 year) provide a tighter feedback loop, and can train your calibration sense quicker. Occasionally, I’ll even make “spot predictions” that resolve by the end of the day – e.g. “Some mysterious work meeting was put on my calendar, what will be announced?” or “Given I run $X miles today, will my pace be less than $PACE?”. The point isn’t that these are incredibly valuable predictions, it’s more an practice in probabilistic thinking à la Thinking in Bets.
Perhaps there’s a distinction to be made between predicting and forecasting. Predicting can be useful on any timescale (i.e. from a single poker hand, to estimating the time until the heat death of the universe), whereas forecasting typically has the implication of a societally-relevant prediction on the years-to-decades timescale.
On Blinding
The first year or two I tracked my predictions, I blinded myself from the prediction score after I made predictions. In other words, I hid the prediction percentage until after resolution. The idea was to prevent myself from biasing what I chose as the resolution by seeing what my prediction was.
In practice, this was a challenge, and not actually that useful. I implemented this by hiding the prediction % column in my spreadsheet, but this made it cumbersome to add new predictions. Additionally, I rarely felt bias one way or the other in doing a resolution – if the criteria didn’t unambiguously resolve YES/NO, I found it easier to resolve as “ambiguous” than pick the self-serving answer.
I have a slight toolmaker’s itch to build something that would automate this tracking (and so would make blinding easier)… Maybe next year.
Questionable Incentives
The real issue with not blinding predictions is that it creates… potentially bad incentives. As a trivial example, predicting “There is a 20% chance I’ll take out the trash today” creates a slight incentive not to do so, and vice versa with “There is an 80% chance I’ll …”.
Honestly, part of the reason I’m writing this post is that I gave a pretty high weight to writing >12 blog posts in 2022 – I’m currently sitting at 11 and looking at the calendar, there aren’t many weeks left.
Is this silly? Yes. Is it a real effect I noticed after doing this for a couple years? Yes.
To be clear, sometimes it’s nice to be surprised by getting one of these adverse incentive predictions wrong. At the beginning of the year I gave myself about a 30% chance of running a half-marathon this year – but I actually did, in July. Even though I scored myself as “incorrect”, it was actually pretty satisfying to do so. At the beginning of the year, there probably was only about a 30% chance, but I back into distance running in the spring, joined a couple running groups, and nudged that probability up significantly.
Conclusion
TL;DR: Try tracking your predictions. You’ll probably notice something interesting. The benefits are pretty similar to keeping a decision log, except as a forward-looking record of your reasoning, instead of backward-looking.
FAQ:
- Why not preregister predictions / make them public?
- I’d rather spend my weirdness points elsewhere. Also, I create predictions pretty regularly, so it’d be a pain to keep up-to-date with a public record.
- How confident are you in the calibration curve?
- Modestly confident, with high error bars. Since I’m making all the predictions ad-hoc, there’s definitely a selection bias in the types of predictions I make. However, since I usually only care about the things I’d like to predict anyways, I think the biased sample is at least representative of the sorts of things I want to improve at estimating.
- Is a Brier Score actually a
good metric for predictions like this?
- Probably not. I calculate it in my spreadsheet for fun, but almost never reference it.
Cover Image: Artist Point @ Mt. Baker
-
Don’t look too closely at these predictions. They’re… pretty off the mark. 😬 ↩︎